SQL语言包括以下几个部分
- 数据定义语言DDL:定义数据库对象
- create
- drop
- alter
- truncate
- 数据控制语言DCL:控制数据库访问权限
- grant
- revoke
- 数据操纵语言DML:对数据库中数据进行操作
- insert
- update
- delete
- 事务控制TCL:管理数据库中的事务,包括提交事务、回滚事务、设置事务的隔离级别等操作。
- commit
- rollback
- 数据查询语言DQL
- select

目录:
关系代数与SQL的转换
| 关系代数运算 | 对应的SQL语句 | 关系代数运算 | 对应的SQL语句 |
|---|---|---|---|
| 选择运算(σ) | WHERE | 连接运算(⋈) | JOIN |
| 投影运算(Π) | SELECT | 赋值运算(←) | AS |
| 并运算(∪) | UNION | 除运算(÷) | NOT EXISTS |
| 差运算(-) | EXCEPT | 去重运算(δ) | DISTINCT |
| 笛卡尔积运算(×) | FROM | 广义投影运算(Π) | SELECT |
| 重命名运算(ρ) | AS | 聚集运算(G) | 聚集函数 |
| 交运算(∩) | INTERSECT | 分组运算(G) | GROUP BY |
SQL数据定义语言DDL
数据库中的关系集合必须由数据定义语言(DDL)指定给系统。SQL的 DDL 不仅能够定义一组关系,还能够定义每个关系的信息,包括:
- 关系的模式
- 属性的取值类型、取值范围(属性域)
- 完整性约束(主外码)
- 关系的安全性和权限信息
- 还包括其它信息如:
- 每个关系维护的索引集合 *
- 每个关系在磁盘上的物理存储结构 *
| 创建 | 修改 | 删除 | |
|---|---|---|---|
| 表 | CREATE TABLE | ALTER TABLE | DROP TABLE |
| 索引 | CREATE INDEX | ALTER INDEX | DROP INDEX |
| 视图 | CREATE VIEW | ALTER VIEW | DROP VIEW |
基本类型
char(n):固定长度的字符串,用户指定长度n。也可以使用全称 character。varchar(n):可变长度的字符串,用户指定最大长度n,等价于全称 character varying。int:整数类型(和机器相关的整数的有限子集),等价于全称 integer。smallint:小整数类型(和机器相关的整数类型的子集)。numeric(p , d):定点数,精度由用户指定。这个数有p位数字(加上一个符号位),其中d位数字在小数点右边。所以在一个这种类型的字段上numeric(3,1)可以精确储存44.5但不能精确存储444.5或032这样的数。real , double precision:浮点数与双精度浮点数,精度与机器相关。float(n):精度至少为n位的浮点数。
create
1 | |
- r为关系名
- A为属性名
- D为属性A的域
- 分号结束
1 | |
notes: primary key声明的属性会自动为 not null
完整性约束
主码约束
primary key(A1,A2,A3)
声明属性A1,A2,A3构成关系的主码,主码属性必须非空且唯一
主键定义可以和属性声明相结合
1 | |
外码约束
foreign key(Ak,…,An)references R
foreign key(dept_name) references department此外码声明表示对于每个课程元组来说,该元组所表示的系名必然存在于department关系的主码属性(dept_name)中。
在上面的代码中,我们定义了一个外键 (foreign key)。外键是用于在两个相关的表之间创建关联的一种约束,确保一个表中的数据引用另一个表中的数据。
dept_name: 这部分指定了当前表中的外键列,也就是包含了部门名称的列。references department: 这部分指定了外键引用的目标表和列。在这里,它表示当前表中的dept_name列引用了名为department的表中的某个列,通常是该表中的主键列(primary key)。
因此,上述代码表示在当前表中创建一个外键约束,将
dept_name 列与名为 department
的表中的某个列进行关联,以确保在插入或更新数据时,所引用的部门名称必须存在于
department 表中,从而保证数据的一致性。
NOTICE:按照数据库理论上说的应该是外键可以为空,为空表示其值还没有确定;如果不为空,刚必须为主键相同。举个例子:有两张表,系信息表,学生信息表,学生信息表中的系号为外键,此时外键可以为空,表示该学生还没有确定所在的系;如果系号不为空则系号必须在系信息表中存在!
not null约束
- not null
一个属性上的 not null 约束表明在该属性上不允许空值。换句话说,此约束把空值排除在该属性域之外。instructor 关系的name 属性上的 not null 约束保证了教师的姓名不会为空。
- SQL禁止破坏完整性约束的任何数据库更新,例如:
- 新插入的元组主码属性为空值、或取值与关系中的另一元组主码属性相同(重复)
- 新插入的student元组所在的dept_name未出现在department关系中,破坏外码约束
alter对属性种类的改变
alter table r add A D;- 为关系中的所有元组增加新属性,所有新属性的取值设为null
- 其中 A 是要被添加到关系 r 的属性的名称,并且 D 是 A 的域。
- 关系中所有元组使用 null 作为新的属性值。
alter table r drop A;- 为关系中的所有元组去掉属性
- 其中,A 是关系 r 的属性的名称
- 许多数据库都不支持删除属性,但支持drop整个表
ALTER TABLE用于在现有表中添加、删除、修改列
- 添加列
1 | |
- 删除列
1 | |
RESTRICT:如果该列被其它列引用,则无法删除该列
CASCADE:引用该列的其它列会和该列同时被删除
- 修改列
1 | |
drop
drop table r;- 删除表和其中的内容
- 删除r的所有元组,删除r的模式
delete from r;- 删除表里的内容,但保留表
- 保留关系r,删除r中的所有元组
级联操作:当使用级联选项(CASCADE)删除学生表时,引用学生表的学生选课表也会被删除。
1 | |
SQL查询的基本结构
1 | |
- A属性
- r关系
- p是谓词,表示符合的条件
- select后可加入的关键词
distinct去除重复all显式指明不去除重复
- SQL查询语句末尾有分号
notes:SQL语句不区分大小写
select
- 对应关系代数中的投影操作\(\Pi\)
- SQL在查询结果和关系中默认允许重复
distinct强制消除重复all指定不消除重复
1 | |
*在select子句中表示“所有属性”select子句可以包含算术表达式,算术表达式中可以有+,-,*, / 运算符和对常量和属性的操作
1 | |
where
- 对应关系代数的选择操作\(\sigma\)
例如:找出Comp. Sci.系中工资大于80000的教师的姓名
1 | |
where子句中可以包含逻辑运算符
and,or,和not逻辑运算符的运算对象可以是包含比较运算符> , >= , <, <= ,=和< > 的表达式
允许使用比较运算符来比较字符串、算术表达式以及日期类型等
| 查询条件 | 谓词 |
|---|---|
| 比较 | =,>,<,>=,<=,!=,<>,!>,!<,NOT+上述比较符号 |
| 确定范围 | BETWEEN AND,NOT BETWEEN AND |
| 确定集合 | IN,NOT IN |
| 空值 | IS NULL,IS NOT NULL |
| 逻辑运算 | AND,OR |
| 字符串运算 | LIKE,NOT LIKE,%,_,ESCAPE |
from
- 对应关系代数中笛卡尔积\(\times\)操作
笛卡尔积instructor × teaches
1 | |
生成每一个可能instructor–teaches对, 所有属性来自两个表
理解为一个迭代(多重循环)的过程
- 如果多关系中存在相同属性,则在select、where子句中须作区分,如:instructor.ID,teaches.ID
对所有上课的教师,查询他们的姓名及课程ID.
1 | |
查询Comp. Sci开的每一门课course ID, semester, year, title
1 | |
natural join
当连接符号为=时,称为等值连接。例4.46为等值连接。
在等值连接中把完全相同的列(比如Student.Sno和SC.Sno)去掉一列为自然连接
- 自然连接会匹配两个关系中所有共同属性的相同值的元组,
去掉重复属性列
- 危险的自然连接:谨防无关的属性具有相同的名字
- 自然连接结果=共同属性+第一个关系属性+第二个关系属性

列出教师的姓名,教师所教的课程的名称
错误做法:
1 | |
instructor natural join teaches的属性有(ID,name,dept_name,salary,course_id,sec_id)course的属性有(course_id,title,dept_name,credits)
这两者自然连接的结果需要在course_id和dept_name这两个属性上取值相同
但此查序会忽略所有这样的(name,title)对:其中教师所授课程不是在他所在的系
也即instructor natural join teaches的dept_name属性不等于
course的dept_name属性
正确做法1:
1 | |
先计算instructor和teaches的自然连接,再计算该结果和course的笛卡尔积
正确做法2:
1 | |
using(course_id): 这是一个连接条件,指定了连接使用的列是
course_id,它是 teaches 表和
course 表共享的列。
r1 join r2 using(A1,A2):在t1.A1=t2.A1
并且t1.A2=t2.A2成立的前提下,来自r1的元组t1和来自r2的元组t2就能匹配。即使r1和r2都有名为A3的属性也不需要A3属性相等
附加的基本运算
更名运算as
old-name as new-nameas子句,即可出现在select子句,也可出现在from子句。
1 | |
as可省去
1 | |
字符串运算
字符串匹配操作符,用于字符串比较
SQL中like运算符可实现模式匹配,模式匹配用两个特殊的字符来表示:
%匹配任意子字符串_匹配任意一个字符
SQL字符串用单引号,关系代数字符串用双引号
- 匹配模式是大小写敏感的(SQL标准);但部分数据库不区分字符串大小写,如MySQL、SQL Server
示例:
‘Intro%’匹配任意以“Intro”开头的字符串。‘%Comp%’匹配任意包含“Comp”子串的字符串。‘_ _ _’匹配只含三个字符的字符串。‘_ _ _ %’匹配至少含三个字符的字符串。
找出姓名中包含“dar”的教师的姓名
1 | |
- 当匹配模式中含有特殊字符(如”%”、”_”、””)时,须使用转义字符(通过escape定义)
like ‘100 \%%’ escape ‘\’:匹配“100%”开头的字符串
like ‘hhhhh#%%’ escape ‘#’:匹配“hhhhh%”开头的字符串
- SQL支持各种字符串操作函数:
- 串联(使用“||”)
- 大写转小写(小写转大写)(
lower(),upper()) - 字符串长度(length()),提取子串(substr()),等等
order by
1 | |
- 可以用 desc 表示降序,使用 asc 表示升序;默认使用升序
- 排序可以在多个属性上进行
1 | |
where子句谓词
between比较运算符(where子句中)
1 | |
可以取代
1 | |
同理可以使用not between
- 元组比较符 不建议使用
1 | |
集合运算
并运算
1 | |
- union运算自动去除重复
- 保留所有重复:
union all
交运算
1 | |
- intersect运算自动去除重复
- 保留所有重复:
intersect all
差运算
1 | |
- except运算自动去除重复
- 保留所有重复:
except all
空值
属性值可以被置为空值,以null表示
空值表示一个未知值或者该值不存在
所有涉及到空的算术表达式的结果为null
使用
is null和is not null来测试空值涉及空值的任何比较运算的结果返回unknown
- 例: 5 < null, null <> null, null = null
三值逻辑处理unknown
OR: (unknown or true) = true, (unknown or false) = unknown (unknown or unknown) = unknown
AND: (true and unknown) = unknown,
(false and unknown) = false, (unknown and unknown) = unknownNOT: (not unknown) = unknown
true > unknown > false
- 如果元组在所有属性上取值相等,那么它们就被当作是相同元组,即使某些值为空
例如:{(‘A’, null), (‘A’, null)}
在去除重复元组(distinct)时,只包留上述元组的一个拷贝
- But,(‘A’, null) = (‘A’, null) 逻辑判断结果为unknown
NOTES:distinct子句和谓词中对待空值的方式不同!
聚集函数
聚集函数是以值的一个集合(集或多重集)为输入、返回单个值的函数
avg: 平均值 min: 最小值 max: 最大值 sum: 总和 count: 计数
其中,sum和avg的输入必须是数字集
当指定DISTINCT选项时,聚集函数要应用在消除重复取值的列上
基本聚集
找出 Computer Science系教师的平均工资
avg(salary)
1 | |
找出在2010年春季讲授一门课程的教师总数
count(distinct ID)
1 | |
找出course 关系中的元组数
count (*)
1 | |
分组聚集group by
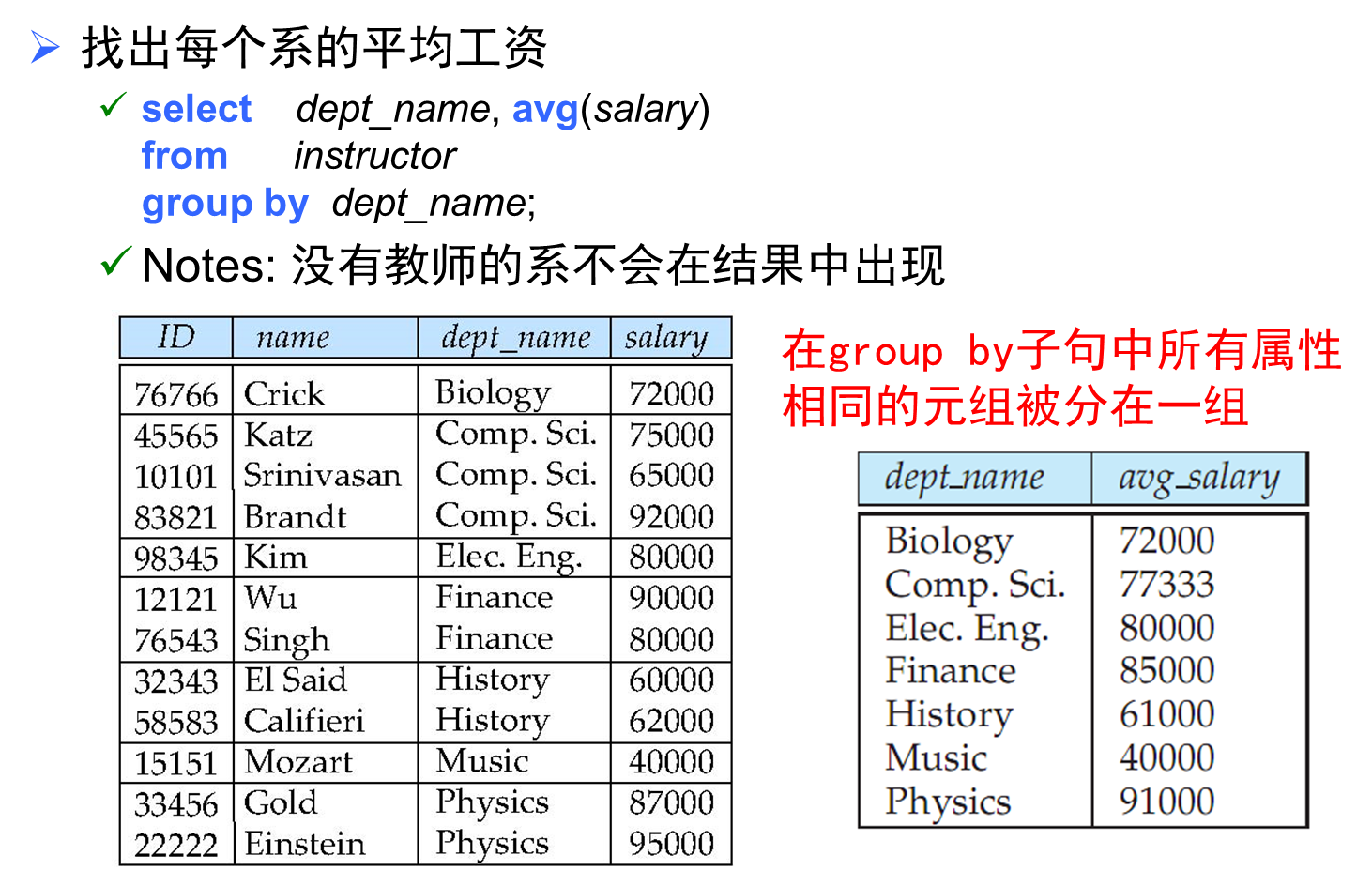
- 出现在 select 语句中但没有被聚集的属性只能是出现在 group by 子句中的那些属性
In other words: 在select子句中出现、但没有在出现group by子句中的属性,只能出现在聚集函数的内部(如sum、count、avg等)
having子句
Notes: having子句中的谓词在形成分组之后才起作用,因此可以使用聚集函数
与select子句类似,任何出现在having子句中但没有被聚集的属性,必须出现在group by子句中
- having子句:分组限定条件
- where子句:元组限定条件
例:找出所有教师平均工资超过 42000 美元的系的名字和平均工资
1 | |
对空值和布尔值的聚集
工资总额的查询
1 | |
sum求和运算忽略输入集合中工资为 null 的值
聚集函数根据以下原则处理空值:
- 除了count(*)之外,所有的聚集函数都忽略输入集合中的空值
- 如果聚集函数输入集合只有空值(即空集)?
- count函数运算返回 0
- 其他聚集函数都返回 null
Notes: 聚集函数一般在select、having子句中使用
AVG(),COUNT(字段名),MAX(),MIN(),SUM()都忽略NULL值
而COUNT(*)对表中行数进行计数,不管是否有NULL
嵌套子查询
- 对集合的成员资格(是否在集合中)
- 集合的比较
- 集合的基数进行检查
集合成员资格测试
找出在2009年秋季和2010年春季学期同时开课的所有课程id
1 | |
找出所有在2009年秋季学期开课但不在2010年春季学期开课的课程id
1 | |
多关系
找出(不同的)学生总数,他们选修了ID为10101的教师所讲授的课程段
1 | |
空关系测试
exist在作为参数的子查询非空时返回true值
not exist在作为参数的子查询为空时返回true值
空关系测试示例:我们还能用另一种方法书写查询“找出在2009年秋季学期和2010年春季学期同时开课的所有课程”
1 | |

from子句中的子查询
找出系平均工资超过$42,000的那些系中教师的平均工资
1 | |
注意不需要使用having子句
lateral关键字

标量子查询

整数除法的精度损失:
- 在除法之前将两个子查询的结果乘以1.0
- 使用cast类型强制转换
数据库的修改(元组数据)
- insert
- update
- delete
delete
删除instructors关系中的所有元组
1 | |
删除Finance 系教师
1 | |
删除所有在位于Watson大楼的系工作的教师
1 | |

insert
将一个新元组插入course
1 | |
等价的方法
1 | |
将一个新元组插入student并且使 tot_creds置为空
1 | |
将所有的教师元组插入student 关系中,同时使tot_creds置为0
1 | |
在执行插入之前先执行完 select from where 语句非常重要,否则:
1 | |
将会导致问题
update

使用case语句
1 | |
case格式:

"<>" 是 SQL 中用于表示不等于的符号。在查询中,"<>" 用于比较两个值,并确定它们是否不相等。这与"="(等于)相对应,表示两个值相等。
例如,如果有一个条件 "age <> 25",它表示选择那些年龄不等于 25 的记录。这种符号通常用于筛选出不满足特定条件的数据。
<>与!=等价

tips
not exists
1 | |
- 这个查询选择了在关系
r中,但不在关系s中的所有元素。 NOT EXISTS只关心子查询是否返回结果,而不关心返回的具体值。子查询返回任何结果,主查询中的条件就被视为满足。select 1中1作为占位符
not in
1 | |
NOT IN要求子查询返回一个包含具体值的结果集。NOT IN在处理 NULL 值时可能需要小心,因为它的行为可能受 NULL 的影响,可能导致意外的结果。
出现在select、having子句但没有被聚集的属性,只能出现在group
by语句中
- 出现在select子句但没有被聚集的属性,只能出现在group by语句中
- 出现在having子句但没有被聚集的属性,只能出现在group by语句中